Lyric Intelligibility Task Overview
Dr Bruno Fazenda, from the Cadenza Team, has shared some ideas of how one could improve lyrics intelligibility. Please visit the link How to Improve Lyric Intelligibility from our Learning Resources.
A. Task overview
Entrants will process pop/rock music to increase the intelligibility with least loss of audio quality. Audio will be evaluated for their intelligibility and audio quality.
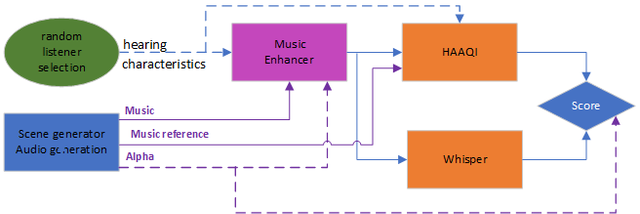
Figure 1. A simplified schematic of the baseline system.
- A scene generator (blue box):
- Selects the stereo music signal.
- Gives a value of (metadata) that sets the balance between intelligibility and audio quality (see evaluation below).
- The music enhancement stage (pink box) takes the music as inputs and attempts to improve the intelligibility.
- Listener characteristics (green oval) are audiograms and compressor settings to allow personalised processing in the enhancement stage and are also used in objective evaluation.
- The enhancement outputs are evaluated using objective metrics (orange boxes):
- For intelligibility using a metric based on Whisper.
- For audio quality via the Hearing-Aid Audio Quality Index (HAAQI) [1].
Systems will also be evaluated by our listening panel.
Your challenge is to improve what happens in the pink, music enhancement box. The rest of the baseline is fixed and should not be changed.
B. Causality
We will accept causal and non-causal systems. Non-causal systems could be used for recorded music, whereas causal systems would also work for live listening. A baseline will be provided for each case. The allowed latency for causal systems will be 5 milliseconds, that is, systems cannot look beyond 5 ms into the future. For details about causality, refer to the Causality webpage.
C. Evaluation
There will be two rank lists, one based on listening tests and the other on objective metrics. It is fine to submit two systems, one optimised for the listening panel and one for the objective metrics.
C.1 Listening tests
The listener panel will score the music for both audio quality and intelligibility. Listeners will be asked to rate music extracts using the follow definitions:
- Lyric Intelligibility: “Lyric intelligibility refers to how clearly and effortlessly the words in the music can be heard.”
- Basic Audio Quality: “Results from judgments of the sound of the music, in relation to a person’s expectations of how the music should ideally sound to them.”
To rank the teams, the intelligibility LI and quality Q ratings from the listening tests will be combined in a weighted average to get an overall score:
Where the weighting will allow the balance between intelligibility and quality to be varied, and indicates a -normalisation to make the two metrics compatible for the weighted average.
We are likely to also ask listeners to rate the samples for Clarity, Distortion and Preference to better understand the results from the perceptual evaluation. But these scales will not be used for rank ordering the systems.
C.2 Objective metrics
Our quality and intelligibility metrics will be combined using Equation (1) as for the listening tests. Audio quality is evaluated using HAAQI [1]. Intelligibility is scored using correct transcribed words ratio (CTW) using a lyric transcription algorithm based on Whisper. HAAQI is an intrusive metrics and the reference will be the original signal with a 1 dB amplification applied to the vocal signal and -1dB to the accompaniment, because that has been shown to be preferred by wearers of hearing aids [3].
Objective metrics are always an approximation and you may want to use other approaches and metrics to optimise a system for the listening panel (for example, you could use singing-adapted STOI [2]).
References
[1] Kates, J. M., & Arehart, K. H. (2015). The hearing-aid audio quality index (HAAQI). IEEE/ACM transactions on audio, speech, and language processing, 24(2), 354-365.
[2] Sharma, B., & Wang, Y. (2019). Automatic evaluation of song intelligibility using singing adapted STOI and vocal-specific features. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28, 319-331.
[3] Benjamin, A.J. and Siedenburg, K., 2023. Exploring level-and spectrum-based music mixing transforms for hearing-impaired listeners. The Journal of the Acoustical Society of America, 154(2), pp.1048-1061.